Skip to content
Skip to content 
Traffic spikes place real pressure on infrastructure, exposing how services interact, how resources are distributed, and how scaling responds to demand.
- Deliberately distribute traffic across availability zones and instances to prevent localized issues from affecting the entire system.
- Separate workloads by function and isolate the data layer with read replicas, connection pooling, and workload isolation to avoid bottlenecks.
- Use scaling signals tied to user impact like queue growth, response time, and error rate; validate with load tests and rollback checks.
Under load, architectural decisions surface through response times, queue behavior, and system coordination, revealing how well an environment is prepared for growth. As concurrency increases, queue lengths lengthen, database latency accumulates, and background processes begin competing for compute. These signals don’t appear randomly — they reflect design choices made long before traffic rises.
Understanding these mechanics helps teams build cloud environments that handle demand predictably and remain stable during periods of sustained activity.
Where Instability Usually Begins
Most high-load incidents follow a similar pattern. The failure is rarely dramatic at first. It starts with small degradations that cascade across layers.
Before discussing solutions, it helps to recognize early technical signals.
Common indicators include:
- Shared services that handle unrelated workloads
- Databases that handle reads and writes on the same instance
- Scaling policies triggered only by CPU metrics
- Synchronous calls between critical services
- Monitoring focused on uptime rather than latency
Each of these choices increases coupling inside the system. Under load, coupling turns into friction.
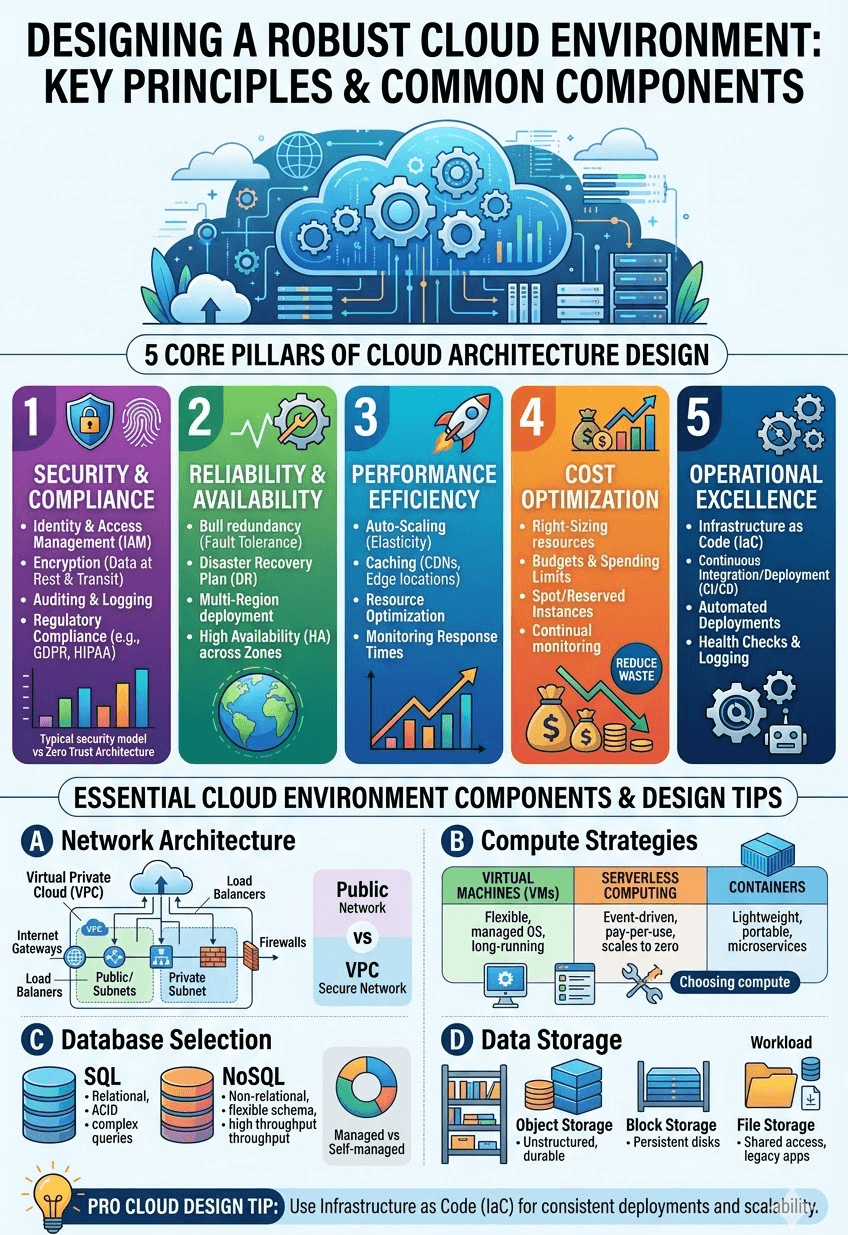
Architectural Decisions That Protect Stability
Designing for heavy traffic means controlling how pressure moves through the system. When traffic increases, the environment must absorb demand instead of amplifying it.
Several design decisions consistently improve stability.
First, traffic distribution must be deliberate. Requests should be routed across availability zones and balanced across instances so that localized issues do not affect the entire system.
Second, workloads must be separated by function. Real-time user requests, background processing, and analytical jobs should not compete for the same resources.
Third, the data layer must be planned with concurrency in mind. Read replicas, connection pooling, and workload isolation prevent storage from becoming a bottleneck.
Finally, scaling logic must respond to signals that reflect real user impact. Queue growth, response time, and error rate provide stronger signals than raw CPU consumption.
These decisions create predictable behavior under pressure.
Operational Discipline Before Traffic Spikes
Architecture alone does not guarantee reliability. The environment must also be observed and tested under realistic conditions.
Before expecting infrastructure to handle peak demand, teams should validate several points.
A practical validation checklist includes:
- Running controlled load tests
- Measuring response degradation thresholds
- Verifying that scaling triggers activate early
- Confirming that rollback procedures function safely
- Reviewing access controls and network segmentation
This type of review exposes limits while changes are still safe to implement.
The Role of Structured Cloud Services
Designing stable cloud infrastructure requires coordination between architecture, automation, monitoring, and security. When these elements are handled independently, gaps appear between them.
Teams that rely on structured cloud services and solutions typically approach the environment as a single operational system. Architecture planning, migration readiness, infrastructure automation, and observability are aligned from the beginning. This alignment reduces the likelihood of unexpected behavior when load patterns shift.
Stability emerges from deliberate planning rather than reactive correction.
Professional Experience Behind Production-Grade Environments
Designing cloud infrastructure that performs reliably under sustained load requires hands-on production experience. The team at Alpacked focuses on environments where architecture, automation, and monitoring must work together under real operational pressure.
Typical work includes:
- Cloud architecture design
- Migration readiness and assessment
- Infrastructure as code implementation
- CI/CD and container orchestration
- Production monitoring and alerting
More than 8 years of DevOps experience across public, private, and hybrid cloud environments, supporting systems running on AWS, Google Cloud, Azure, Kubernetes, and serverless platforms.
The Real Outcome of Thoughtful Architecture
Cloud platforms are capable of processing significant demand. Whether an environment remains stable depends on how carefully it is designed.
When traffic distribution, workload separation, scaling logic, and observability are treated as connected design decisions, growth becomes manageable. Without that preparation, even a moderate load can expose weaknesses.
A cloud environment that withstands pressure is not accidental. It is the result of deliberate architectural planning and disciplined execution.