 Skip to content
Skip to content 
The True Cost of Data Corruption in Modern Web Scraping
Poor-quality input does more than skew dashboards; it systematically undermines business intelligence and drains budgets. Gartner pegs the average annual cost of bad data at US $12.9 million per enterprise.
This staggering figure encompasses re-work hours, strategic decision delays, and missed revenue opportunities that stem directly from corrupted datasets.
But this is just the tip of the iceberg. According to recent industry analyses, organizations typically waste 30% of their data collection budgets on unusable information that must be cleansed or discarded entirely.
For enterprise-scale operations, this translates to millions in operational inefficiency.
Where Does Data Corruption Originate?
The primary sources of data pollution in web scraping operations include:
Shadow duplication: Multiple scrapers hitting the same endpoint through unverified IP ranges trigger duplicate records when CAPTCHAs or geo-blocks alter page layouts.
These duplicates often contain subtle variations that evade standard deduplication algorithms, creating phantom inventory, price discrepancies, and false trend signals.
Stealth throttling: Modern bot management systems have evolved beyond simple blocking. Today’s sophisticated defenses inject subtle payload changes, incorrect prices, and reordered HTML tags specifically designed to fool “budget” scraping scripts rather than block them outright.
This creates a dangerous scenario where data appears valid but contains strategically corrupted elements.
Latency bias: High round-trip times from congested proxy nodes lead crawlers to time-out on dynamic elements, silently dropping key fields.
This creates systematic blind spots in datasets, particularly affecting JavaScript-rendered content like reviews, inventory counts, and time-sensitive pricing.
Content fingerprinting: Advanced anti-bot systems now tailor content based on visitor characteristics, including IP reputation, browser fingerprint, and navigation patterns.
Scrapers using compromised proxies receive deliberately altered information, creating data inconsistencies that propagate throughout the analytics pipeline.
All these issues sabotage data integrity long before an analyst opens a spreadsheet. Treating proxies as disposable commodities only widens the error margin and compounds these problems.
Why Proxy Hygiene Is a Compliance Issue?
Scraping failures rarely stay confined to the analytics team. IBM’s 2023 Cost of a Data Breach report puts the average incident at US $4.45 million, up 15% since 2020. While that study focuses on breaches, its root lessons map directly to scraping workflows:
Compliance Risks of Poor Proxy Management
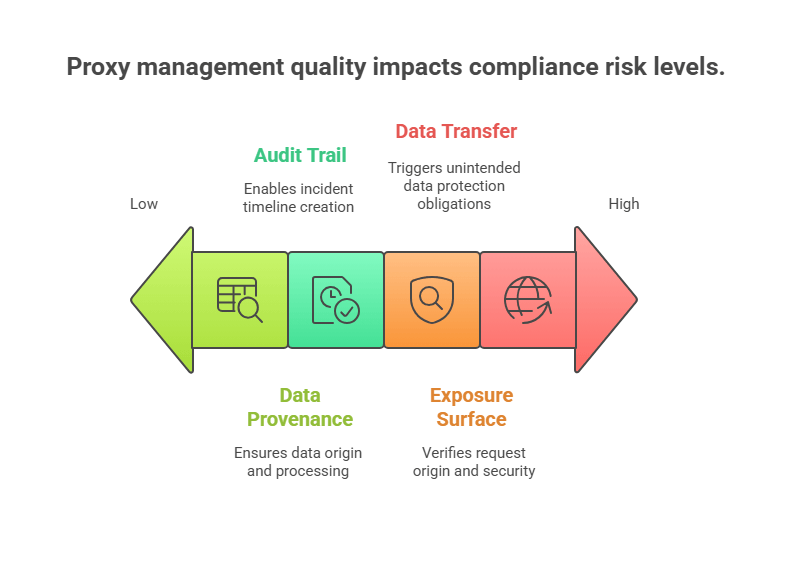
Unknown exposure surface: Using opaque “free” proxy lists makes it impossible to verify whether outgoing requests piggyback on compromised residential devices—an instant compliance red flag under GDPR and CCPA.
European regulators have specifically targeted companies using compromised residential proxies, with fines reaching up to 4% of global annual revenue.
Audit-trail gaps: Security teams can’t produce incident timelines when proxy rotations are undocumented, jeopardizing mandatory disclosures under the U.S. SEC’s new four-day cyber-incident rule. These documentation failures create regulatory vulnerability even when the underlying scraping activity is legitimate.
Data provenance doubts: When ingestion pipelines mix clean and tainted rows, data lineage collapses, eroding stakeholder trust and increasing the likelihood of costly re-collection cycles. Under GDPR’s “right to explanation” provisions, organizations must be able to document the origin and processing of all data points—impossible when using unvetted proxies.
Cross-border data transfer violations: Undocumented proxy usage can inadvertently route requests through jurisdictions with stringent data protection laws, triggering compliance obligations companies aren’t prepared to meet. This is particularly problematic for financial and healthcare data.
In other words: robust proxy governance is risk management at its core. A budget saved on unvetted IPs can morph into seven-figure legal expenses months later, not to mention reputational damage that lingers far longer.
Building a Continuous Quality Loop: Measure, Rotate, Verify
Scraping teams that thrive in today’s bot-dense landscape treat proxies as living infrastructure, not static plumbing. A three-step continuous improvement loop keeps that infrastructure honest and resilient.
1. Baseline Every Node
Record median latency, successful handshake rate, and HTTP status distribution during off-peak hours. Anything beyond two standard deviations becomes a quarantine candidate. Implement these specific baseline measurements:
- TLS fingerprint consistency: Verify that each proxy maintains consistent cryptographic characteristics to detect man-in-the-middle interceptions.
- Geographic accuracy: Confirm that proxies resolve to their claimed locations using multiple verification services.
- Response integrity: Compare scraped data against control samples to detect content manipulation.
- Header pass-through: Ensure custom headers remain unmodified when traversing the proxy network.
These comprehensive baselines establish a quality foundation for all subsequent scraping activities.
2. Rotate Intelligently
Swap IPs based on empirical health scores, not rigid timers. High-quality residential nodes stay in rotation longer; flaky datacenter addresses retire early to conserve CAPTCHAs and bandwidth. Implement these rotation strategies:
- Performance-based rotation: Replace proxies when their response times exceed predetermined thresholds rather than on fixed schedules
- Behavioral adaptation: Adjust rotation frequency based on target site behavior patterns and anti-bot measures
- Risk-balanced distribution: Allocate higher-quality proxies to mission-critical targets while using standard proxies for less sensitive endpoints
- Traffic pattern normalization: Randomize request intervals to mimic human browsing patterns, reducing detection probability
Smart rotation strategies maximize proxy efficiency while minimizing detection risk.
3. Run Automated Proxy Tests Before Every Major Crawl
Look for anomalies such as sudden TLS fingerprint mismatches or unexplained redirects. The proxy test reduces the risk of contaminated data entering your pipeline.
Flagged nodes feed back into step 1, closing the loop. Implement these pre-crawl verification steps:
- Canary requests: Send known-pattern requests to benchmark sites and validate response integrity.
- Header inspection: Verify that proxies aren’t adding, removing, or modifying HTTP headers.
- JavaScript execution: Confirm proper rendering of dynamic content through headless browser tests.
- Rate-limit probing: Test response patterns at increasing request frequencies to identify throttling thresholds.
Key Performance Indicators for Proxy Health
| KPI | Acceptable Range | Diagnostic Action if Breached |
|---|---|---|
| Median handshake latency | < 250 ms | Reroute through lower-hop ISP or alternative ASN |
| Block-induced HTML diff rate | < 3% | Inject headless browser fallback |
| Duplicate record ratio | < 0.5% | Tighten canonicalization logic + validate proxy pool |
| SSL/TLS validation failures | < 0.1% | Audit certificate chain and rotation schedule |
| Geolocation accuracy | > 95% match | Refresh proxy metadata and verify provider claims |
| JavaScript rendering success | > 98% | Upgrade browser automation tools and increase timeouts |
Teams that implement this continuous improvement loop report cleaner datasets, lower cloud expenditures (due to reduced retry attempts on doomed requests), and significantly improved analytical outcomes.
Advanced Proxy Management Strategies for Enterprise Scraping
Proxy Segmentation and Specialization
Rather than treating all proxies as interchangeable, leading organizations implement tiered proxy architectures:
- High-fidelity proxies: Reserved for financial data, competitive intelligence, and other business-critical targets.
- Standard proxies: Used for routine monitoring and less sensitive targets.
- Residential vs. datacenter mix: Strategically deployed based on target site sophistication and anti-bot measures.
- Dedicated session proxies: Maintain consistent identity for multi-page workflows requiring login sessions.
This segmentation optimizes resource allocation while maximizing data quality where it matters most.
Proxy Provider Evaluation Framework
When selecting proxy providers, evaluate them against these criteria:
- Transparent sourcing: Do they clearly document how their proxies are acquired?
- Compliance documentation: Can they provide evidence of consent for residential proxies?
- Geographic accuracy: Do independent tests confirm their location claims?
- Stability metrics: What percentage of their IPs remain viable over 30/60/90 day periods?
- Rotation controls: Do they offer granular control over rotation timing and patterns?
- Response to blocks: How quickly do they replace proxies identified as blocked?
A structured evaluation process reduces compliance risk and improves operational reliability.
Synthesis: The Strategic Value of Proxy Discipline
Web scraping now operates in an environment where one in three visitors is a malicious bot. That reality magnifies the downstream cost of every sloppy proxy decision, from skewed dashboards to multi-million-dollar compliance violations.
By baselining each proxy, rotating based on performance triggers, and running comprehensive verification tests before launch, you transform your proxy fleet from a leaky hose into a precision instrument.
Your data scientists will thank you for the silence of a dataset that finally speaks clearly, and your compliance team will sleep better knowing your data collection practices meet regulatory standards.
In today’s data-driven business landscape, the quality of your intelligence is directly proportional to the quality of your collection infrastructure.
Organizations that treat proxy management as a strategic capability rather than a technical nuisance gain sustainable competitive advantage through superior data integrity, reduced compliance risk, and more reliable business intelligence.






